
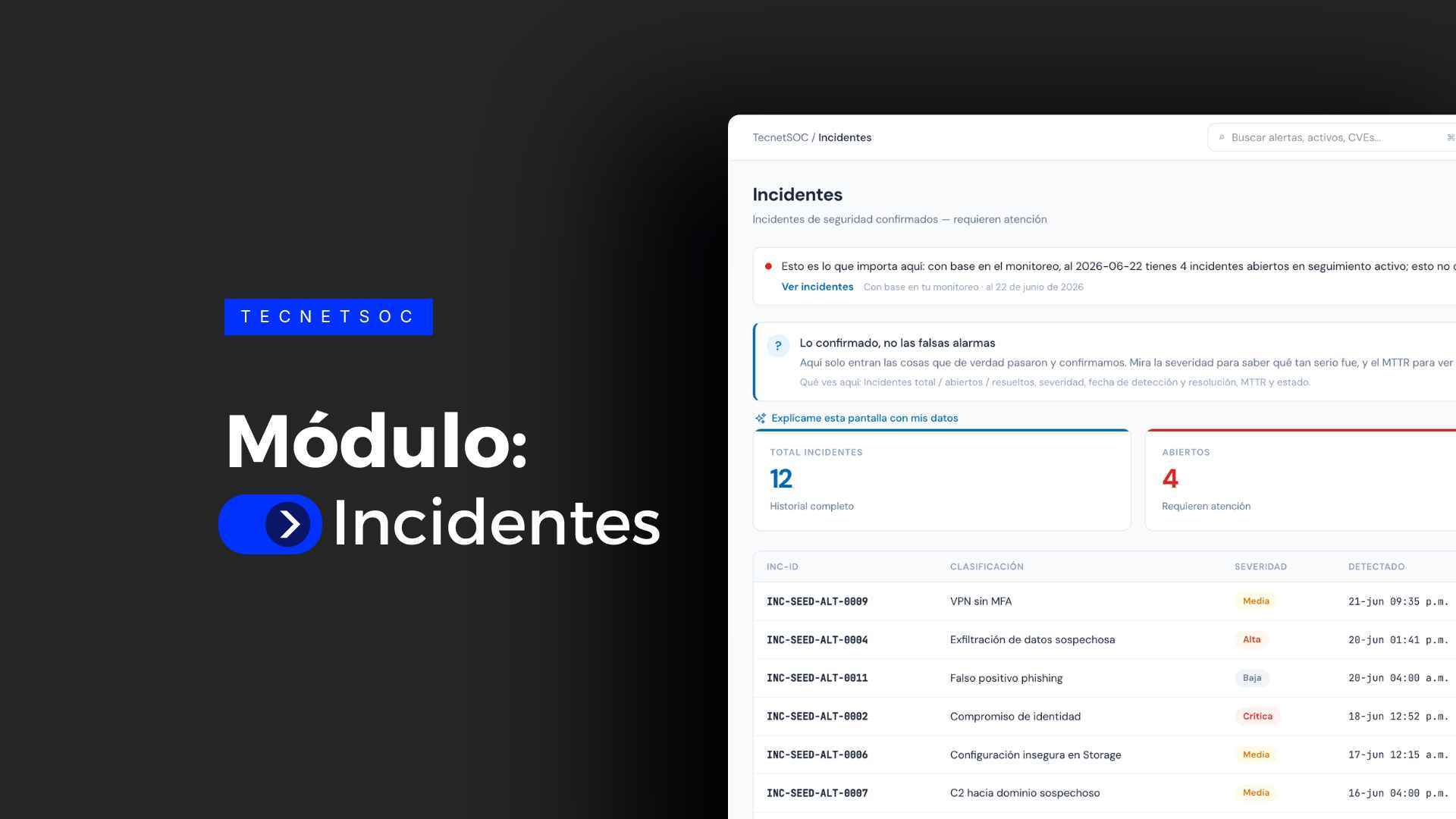
El módulo de Incidentes de TecnetSOC consolida en un solo lugar todos los incidentes de seguridad confirmados y los acompaña por su ciclo de vida completo. Cada incidente lleva su severidad, su clasificación bajo MITRE ATT&CK, su MTTR calculado de forma automática y su estado en tiempo real, siempre enlazado con la investigación que lo originó.
Es la pieza que ordena la gestión de incidentes de seguridad una vez que la amenaza ya se confirmó. No se trata de detectar, porque de eso se encargan otras capas del SOC, sino de responder con precisión a las preguntas que siempre llegan después: cuánto tardamos en cerrarlo, quién lo atendió, qué tan grave fue y con qué táctica de ataque se relaciona.
En la mayoría de los equipos esa información existe, pero vive fragmentada entre correos, capturas y la memoria del analista de guardia. Y lo que está fragmentado no se puede medir ni demostrar.
Cuando llega una auditoría ISO 27001 o un cliente pregunta por los tiempos reales de respuesta, esa diferencia entre "lo resolvimos" y "puedo demostrar cómo lo resolvimos" es justo lo que el módulo cierra.
El problema no es detectar, es gestionar lo que sigue
Detectar una amenaza es la parte visible del trabajo de un SOC, pero rara vez es donde se pierde el control. Lo que se descontrola es el ciclo de vida posterior. Una alerta se confirma como incidente real y, a partir de ahí, empieza una carrera por contenerlo, resolverlo y documentarlo que muchas veces ocurre sin un tablero común.
El síntoma típico es este: el incidente se resolvió, sí, pero nadie puede responder con precisión cuánto tardó, quién lo atendió, qué tan grave fue en realidad ni con qué táctica de ataque se relaciona. Esa información existe, pero está fragmentada. Y lo que está fragmentado no se puede medir ni mejorar, mucho menos demostrar.
Para una empresa que opera bajo marcos como ISO 27001 o que rinde cuentas a un cliente sobre su postura de seguridad, esto deja de ser un detalle operativo. La pregunta deja de ser "lo resolvimos" y pasa a ser "puedes demostrar cómo, cuándo y con qué criterio lo resolviste". Ahí es donde una gestión de incidentes ordenada se vuelve tan importante como la detección misma.
Cómo funciona el módulo de Incidentes de TecnetSOC
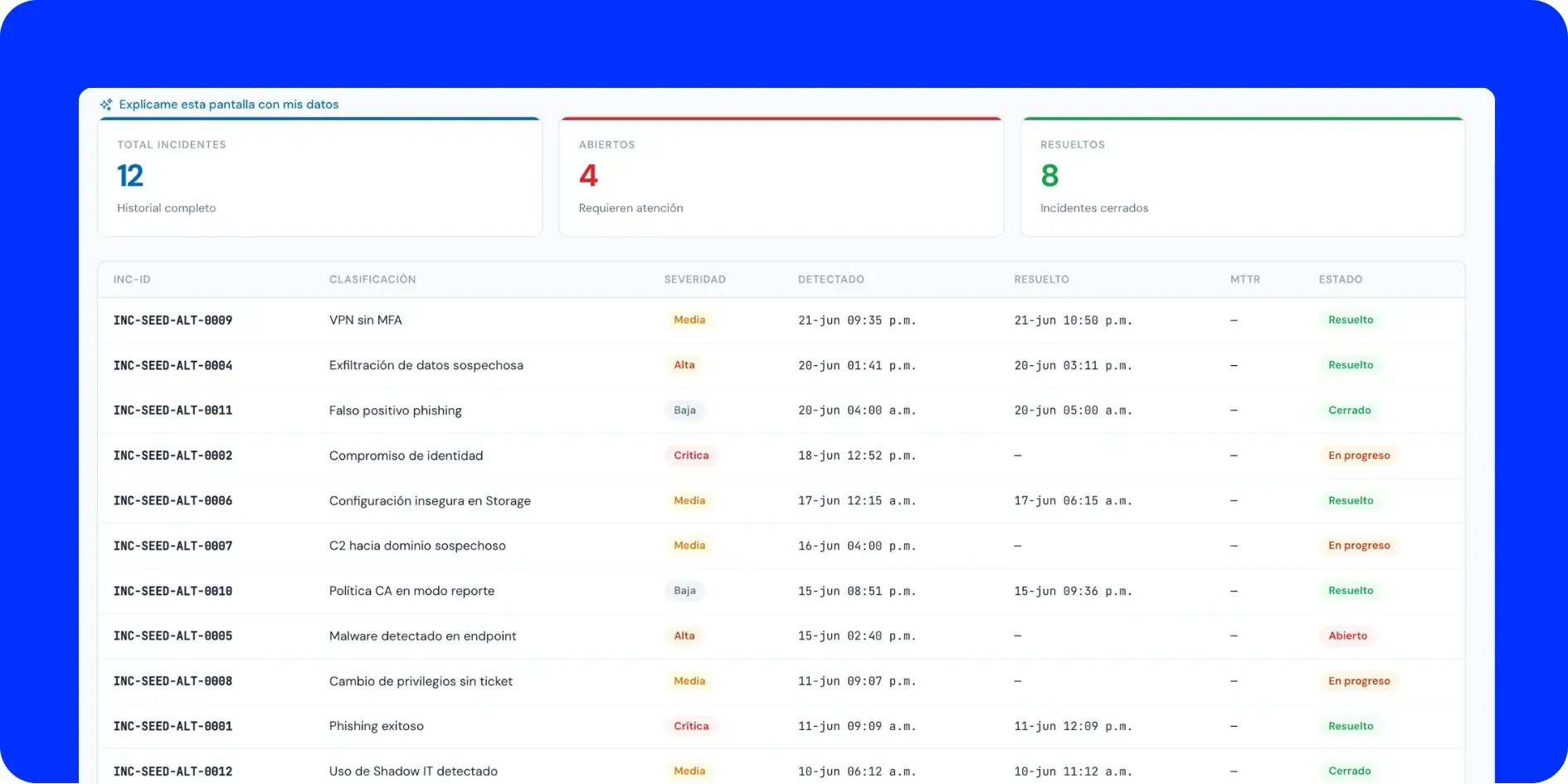
El módulo consolida en el portal todos los incidentes de seguridad confirmados y los acompaña a lo largo de todo su ciclo de vida, desde que se registran hasta que se cierran formalmente. Cada incidente queda enlazado con la investigación que lo originó, de modo que la trazabilidad nunca se rompe: se puede ir hacia atrás y entender por qué ese incidente existe. Esta integración es una de las ventajas de operar con un servicio gestionado frente a montar todo en casa, como vimos al comparar el SOC interno contra el SOC como servicio.
Severidad, clasificación y estado: el lenguaje común del incidente
Cada incidente se registra con una severidad definida (crítica, alta, media o baja). Así el equipo trabaja con un mismo criterio de prioridad y no con interpretaciones sueltas. La clasificación se apoya en MITRE ATT&CK (el marco de referencia de tácticas y técnicas de ataque más usado en la industria) y por tipo de amenaza, lo que permite entender no solo qué tan grave es un incidente, sino con qué clase de comportamiento adversario se relaciona.
El estado se sigue en tiempo real a lo largo de las fases del ciclo: abierto, en progreso, resuelto y cerrado. Esto elimina la ambigüedad de "creo que ya se atendió". Cualquier persona del equipo, o el propio cliente, puede entrar al portal y ver en qué punto está cada incidente sin tener que escribirle a nadie.
MTTR automático: medir el tiempo de resolución sin hojas de cálculo
El módulo calcula de forma automática el MTTR (Mean Time To Resolve, o tiempo promedio de resolución) de cada incidente, usando los timestamps de detección y de cierre que el propio sistema registra. Esto convierte una métrica que normalmente se estima de memoria en un dato real y verificable, incidente por incidente.
El MTTR no es un número de vanidad. Es la base para saber si el equipo está mejorando con el tiempo, para detectar qué tipos de incidente cuestan más trabajo cerrar y para sostener una conversación honesta con la dirección o con un cliente sobre los tiempos reales de operación.
Historial completo y coordinación con el analista de guardia
Cada incidente conserva su historial completo con los timestamps de detección y cierre, de forma que el registro queda como evidencia consultable y no como un recuerdo. En los incidentes activos de severidad alta y crítica, el módulo contempla la coordinación directa con el analista del SOC. Así el cliente no queda solo frente a un evento grave: hay una persona del lado de TecnetOne acompañando la gestión mientras el incidente sigue abierto.
El impacto operativo: de un incidente suelto a un ciclo trazable
La diferencia práctica entre gestionar incidentes con esta estructura y gestionarlos a mano no es estética, es de control. Cuando cada incidente confirmado tiene severidad, clasificación, estado y MTTR en un mismo lugar, el equipo deja de invertir tiempo en reconstruir qué pasó y lo dedica a resolver lo que sigue.
Para la operación diaria, esto significa que el estado de seguridad de la empresa se puede leer de un vistazo en lugar de armarse a base de preguntas. Para la dirección, significa tener métricas reales (cuántos incidentes críticos hubo, cuánto se tardó en cerrarlos, cómo evoluciona el MTTR) sin depender de que alguien las recopile a mano cada mes.
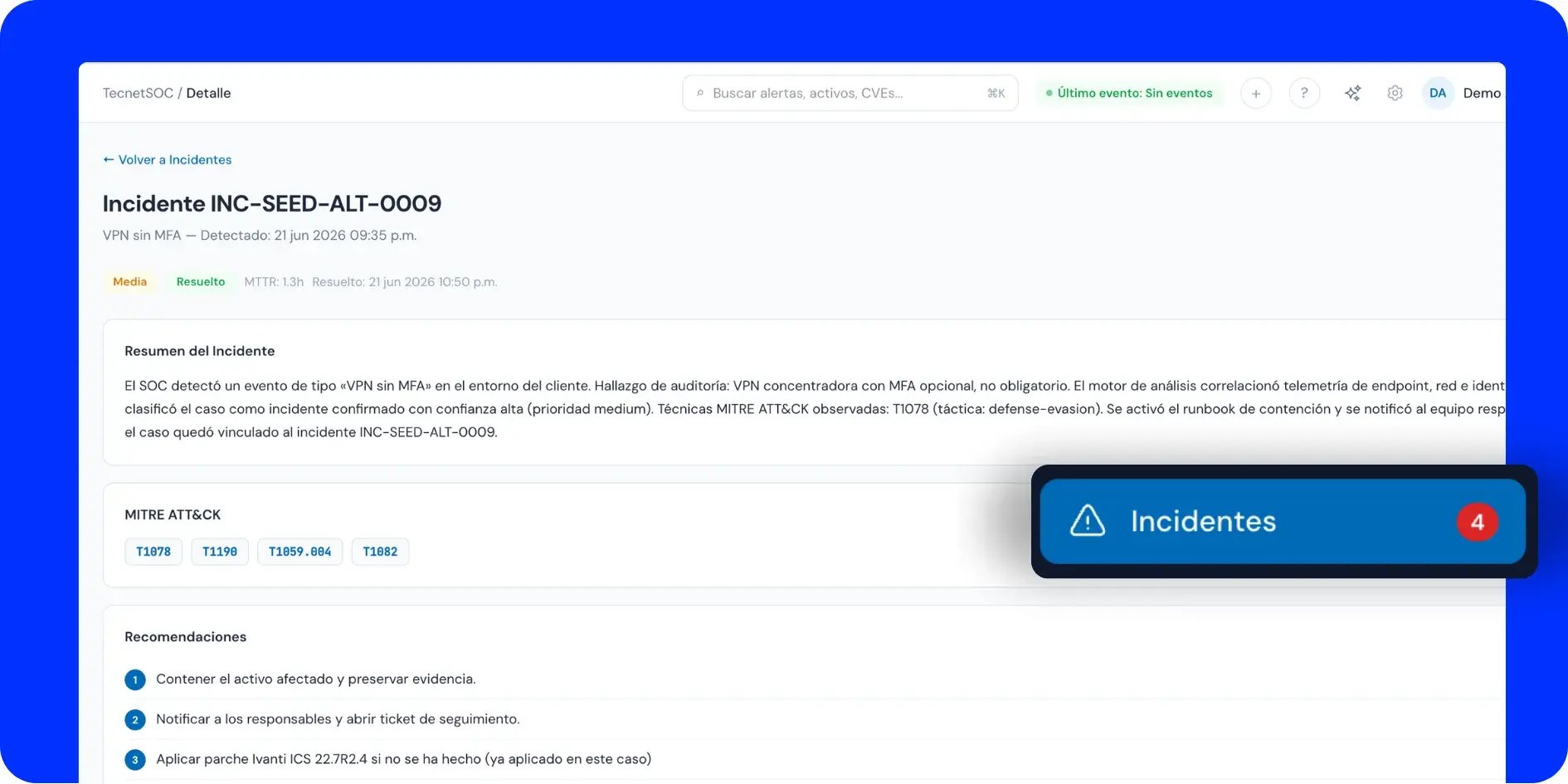
Y para los procesos de auditoría o de cumplimiento, el valor es directo. Un historial de incidentes con timestamps, severidad y clasificación es justamente el tipo de evidencia que un SOC genera para auditorías de ISO 27001, PCI DSS o LFPDPPP.
Esa estructura es, además, la base sobre la que se apoya un buen plan de respuesta a incidentes. Si quieres entender qué tan preparada está tu operación para ese escrutinio, vale la pena revisar si tu empresa está lista para una auditoría de seguridad.
Checklist: cinco preguntas sobre tu gestión de incidentes
Si quieres ubicar rápido en qué punto está hoy tu manejo de incidentes confirmados, estas cinco preguntas ayudan a aterrizarlo. Mientras más respondas con un "no sé con certeza", más valor te dará ordenar el ciclo de vida:
- Si te preguntan ahora mismo cuántos incidentes críticos tuviste el mes pasado, puedes responder con un número exacto sin abrir varios sistemas.
- Tienes claro cuánto tardaste, en promedio, en cerrar tus últimos incidentes de severidad alta.
- Cada incidente cerrado tiene registrado quién lo atendió, cuándo se detectó y cuándo se cerró.
- Puedes decir con qué táctica o técnica de ataque se relacionó cada incidente reciente.
- Tu equipo y tu cliente ven el mismo estado del incidente sin tener que preguntárselo entre sí.
Este tipo de visibilidad es la que TecnetSOC integra de forma nativa, junto con la detección, la investigación y el monitoreo continuo.
